*참고 : 이탤릭 글자들은 논문속의 내용이 아닌 제 생각을 주절주절 적은 것이니 아닐 수 있습니다.
Author
- Nikita Kitaev, Lukasz Kaiser, Anselm Levskaya
Abstract
- 큰 사이즈의 트랜스포머 기반 모델들은 여러가지 분야에서 SOTA를 달성
- 하지만, 모델들을 학습하는데 비용이 많이 듬 : 특히 긴 시퀀스의 경우
- 그래서 트랜스포머를 효율을 향상시킬 두가지 기술을 소개하려 함.
- 어텐션을 계산할 때 내적 대신 LSH(Locality-Sensitive Hashing)을 이용
⇒ O(L^2) → O(LlogL) - 기존의 residuals 방법 대신 "reversible residual layer"를 사용
⇒ 학습시 엑티베이션을 한 번만 저장하도록 변경(기존에는 layer수 만큼 저장)
- 어텐션을 계산할 때 내적 대신 LSH(Locality-Sensitive Hashing)을 이용
- 실험을 통해 기존 트랜스포머 모델과 동등한 성능을 유지하면서 긴 스퀀스에 대해서도 훨씬 메모리와 속도 측면에서 효율적이고 빠름을 보임.
1. Introduction
1.1 Large-scale & Long-sequence를 위한 리소스 과다 필요 문제
- 트랜스 포머 아키텍쳐는 자연어 처리에 널리 사용되지며 여러 분야에서 SOTA결과를 제공
- 하지만, 좀더 좋은 성능을 얻기 위해서 점점 더 큰 모델로 발전하고,
- 또한 다양한 Task에서 사용하려 하다 보니 한 번에 처리해야할 입력의 길이가 긴 Task들에서도 사용하고자 하는 시도가 많아짐.
- 즉, "Large-scale&Long-sequence" 형태로 발전 하지만, 이러한 모델은 좋은 결과를 제공하지만, 너무 많은 리소스를 필요로 함.
- 최근의 자연어처리 연구는 결국 아이디어가 아닌 돈 으로 데이터 많이 사고 돈으로 컴퓨팅 리소스 많이 사는 놈이 장땡인 분위기 까지 흐름.
1.2 왜 이런 문제가 생기는가?
- 매우 큰 사이즈의 트랜스포머 모델은 기본적으로 그런 거대한 리소스가 필요한 것인가?
아니면 비효율 적인 부분들이 있는 것인가? - "Mesh-TensorFlow : Deep Learning for Supercomputer"
- 현재 가장 큰 모델인 것 같다고 저자가 이야기 함.
- 각 레이어 별로 0.5B 파라메터 저장을 위해 2GB가 필요.
- 64k 길이의 토큰(Embedding Size : 1K)이고 배치 사이즈가 8이라고 하면, Activation 저장을 위해 한번에 또 다른 2GB가 필요
- 위의 내용을 보면 우리가 만약 각 레이어 별로 따로 메모리를 사용한다면, 단일 머신에서도 쉽게 큰 트랜스포머를 학습 가능.(게다가 BERT를 학습하기 위한 전체 말뭉치도 17GB 밖에 안되니..)
- 그렇다면, 각 레이어 별로 독립적으로 메모리를 사용하지 못하는 이유는 무엇?
- 이 것에 대한 해결책으로 1.3 방법들을 사용한 Reformer를 제안
- 참고 : 위 계산은 레이어당 메모리 및 입력 활성화 비용 만 포함되어 있으며, 다음을 포함한 다른 주요 메모리 사용 소스 들은 고려하지 않았음.
- 역전파를 위해 activations이 저장 되어 져야 하기 때문에, 레이어가 n개인 경우 한 개짜리 모델보다 n배더 크다.
- 중간 FF-layer 층의 깊이가 전체 인코더 레이어 층보다 클수 있기 때문에 메모리 사용의 상당 부분을 차지 할수도 있음.
- 참고 : 위 계산은 레이어당 메모리 및 입력 활성화 비용 만 포함되어 있으며, 다음을 포함한 다른 주요 메모리 사용 소스 들은 고려하지 않았음.
1.3 Reformer의 Key-idea
- Reversible layer : 백프로파게이션 시에 엑티베이션 값을 저장하지 않아도 됨
- 청크 단위로 저장.
- 어텐션 계산시 LSH사용
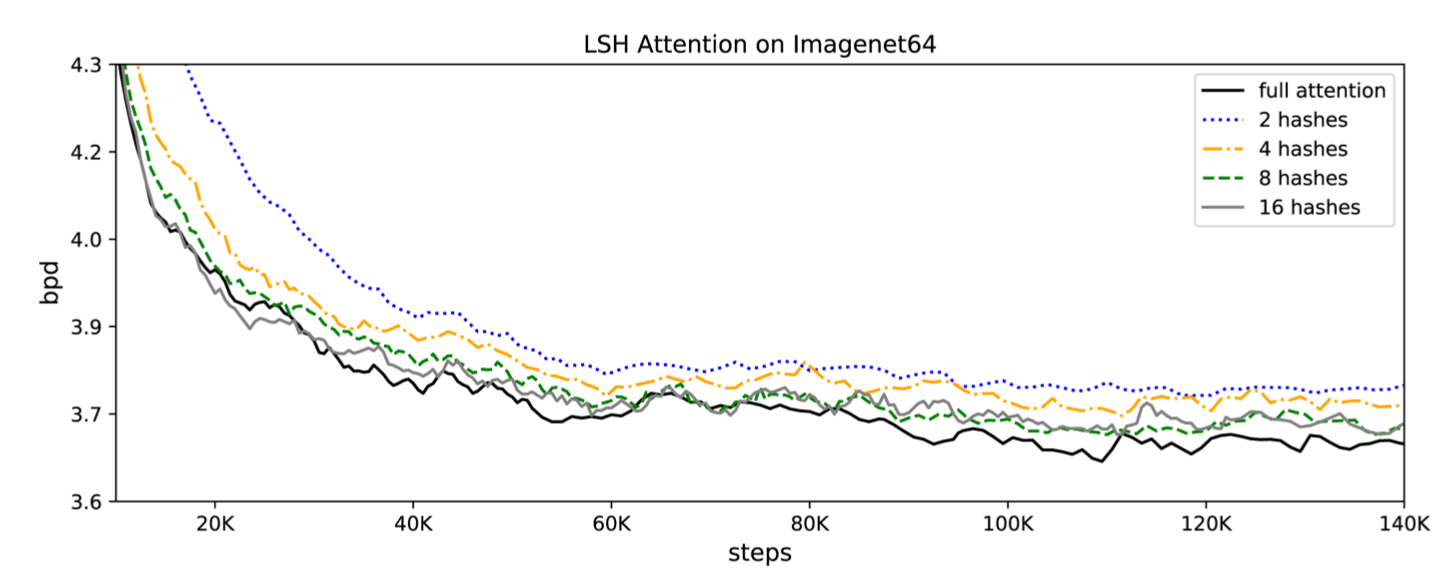
1.4 실험해 보니..
- 실험을 통해 기존 트랜스포머와 비교하여 학습과정에서 무시 가능할 정도의 영향만 있다는 것을 보여줌.
- 단, LSH 사용시의 버킷 수에 따라 학습에 영향을 줄수 있음.
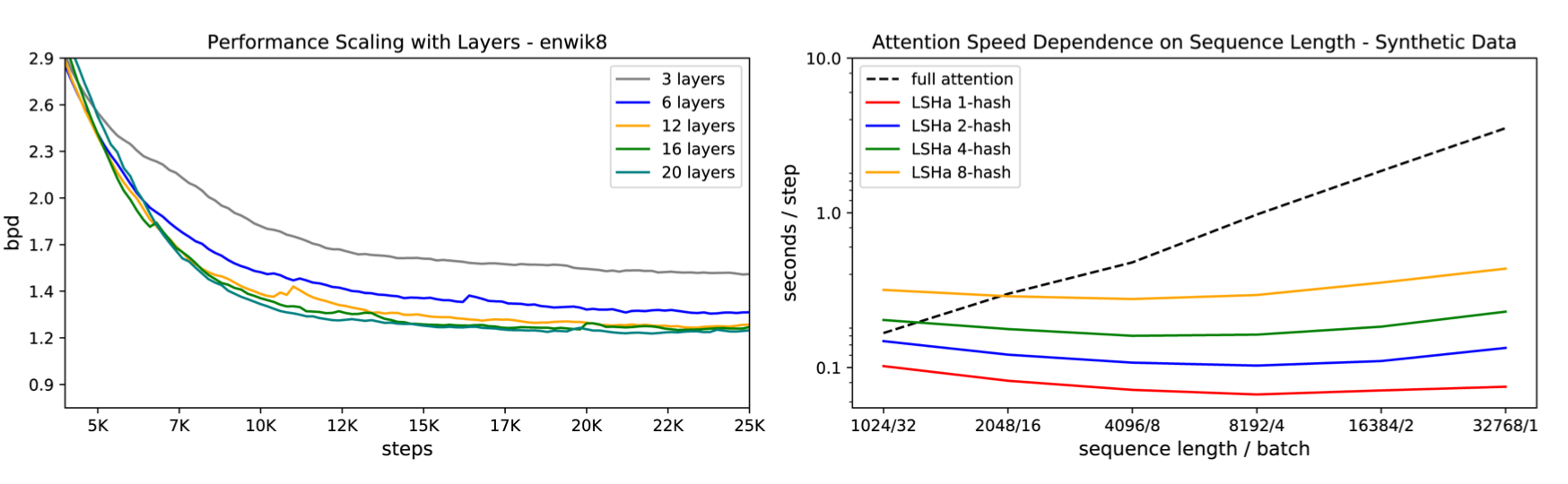
- 64k 시퀀스의 텍스트 처리(en wiki8)과 12k시퀀스 이미지 생성 작업을 실험하여 모두 기존 트랜스포머와 같은 결과를 얻지만, 속도와 메모리 효율성이 높은 것을 증명해 냄.
2. LOCALITY-SENSITIVE HASHING ATTENTION
Dot-product attention
- 걍 우리가 다 알고 있는 어탠션에 대한 설명.
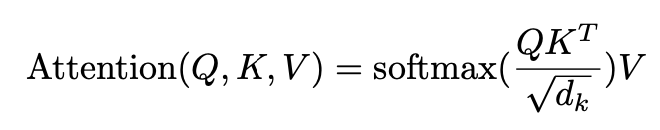
Multi-head attention
- 걍 우리가 다 알고 있는 멀티 헤드 어탠션 설명.
Memory-efficient attention
- 어텐션 계산시 Q, K, V 모두 [batch_size, length, dmodel] 의 크기를 가진다고 가정.
- 이 경우 length가 매우 길 경우 문제는 QK^T : [batch_size, length, length]
- Length가 64k라고 하면, batch_size가 1이라고 해도 16GB가 필요
- 이것은 실용적이지 않으며 긴 시퀀스에서 트랜스포머 사용을 방해하는 요소임.
- 그러나 생각해 보면, QK^T 행렬을 메모리에 모두 올리는게 중요한게 아님.
- 실제로 qi하나에 대해서 각각 계산해 두었다가, 백 워드 패스 때 그래디언트 계산시 사용하면 더 효율적 일 수 있음.
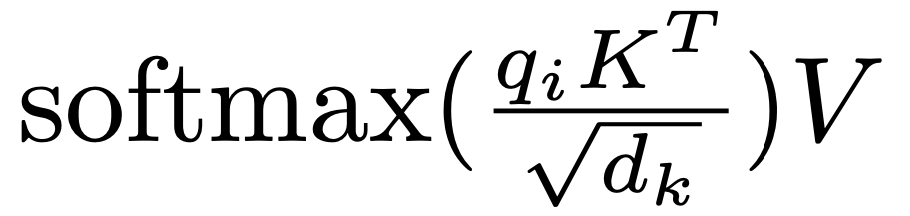
Where do Q, K, V come from?
- Q, K, V는 결국 하나의 엑티베이션 행렬로 부터 계산 되어짐 (3개의 linear layer를 사용)
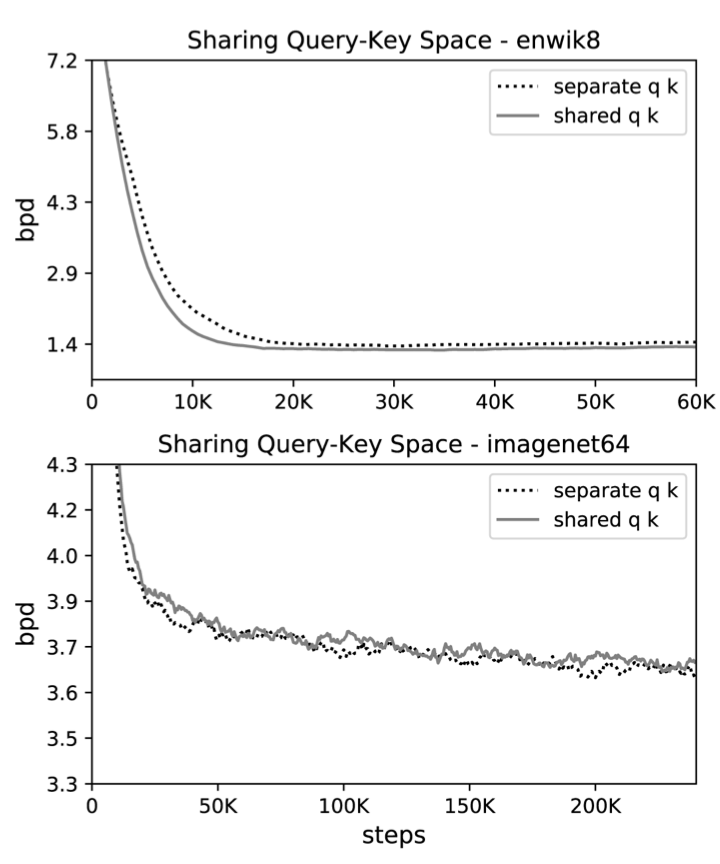
- LSH attention을 위해서 query들과 key들은 같아 지길 원함
- 이 것은 같은 하나의 linear layer를 사용하면 쉽게 가능해짐
- (내생각)사실 RNN 기반 Encoder-Decoder에서는 Decoder쪽 Query와 Encoder쪽 Key가 다르니 당연한 어프로치 였었지만, self-attention은 Query와 Key가 같은데 굳이 다르게 계산하는 게 맞는지가 항상 궁금 했었고, 왠지 걍 attention으로 부터 계산이 오다 보니 다른 메트릭스 곱을 쓰는 형태로 처음에 만들어진 느낌이었었음. 즉, 사실 당연히 같은 값을 사용하는 것이 맞아 보였음. 유사도를 보는 것이니께...
- 이것을 shared-QK Transformer 라고 부르고, 이것은 Transformer의 성능에 영향을 주지 않음.
Hashing attention
- LSH attention을 위해서 2개의 텐서를 가지고 시작(Q=K, V) [batch_size, length, dmodel]
- 대신 multi-head attention이나 attention 계산 방식은 그대로 유지.
- QK^T를 계산 시 문제가 있지만, 우리가 관심 있는 것은 softmax(QK^T).
- softmax는 가장 큰 값 들에 의해 결정되어 지므로, 각 qi별로 가장 가까운 key들에만 포커스 해도 됨.
- (내 생각)어탠션이라는 것이, 결국 Query와 Key간의 유사도를 이용해서 어탠션 웨이트를 정하고, 해당 Value값에 그 웨이트를 곱한 것의 합 이기 때문에, Key의 숫자가 많다면, 유사한 단어 몇 개를 제외하고는 대부분 아주 작은 값을 가지는 롱테일 형태 일 것임.
- (내생각)게다가 softmax의 특징상 해당 롱테일 값들이 크게 영향을 미치지 않기 때문에 가장 유사한 N개의 Key만을 이용해서 어탠션을 계산해도 softmax의 결과 값은 바뀌지 않을 것임.
- 예를 들어 lenght 가 64K 일 때, 각 query별로 가까운 32~64개 정도의 키만 봐도 충분할 것임.
- 그렇다면, 각 qi에 대해 가까운 유사도를 가진 key들을 어떻게 결정할 것인가?
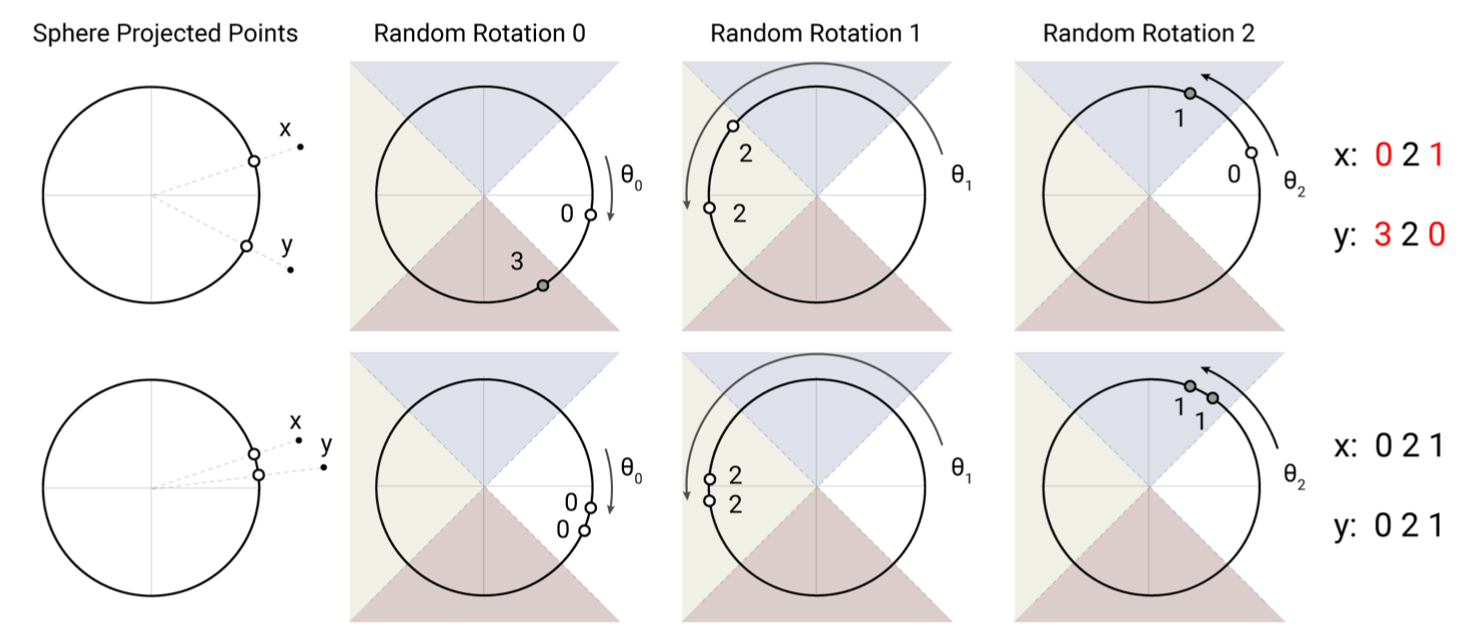
Locality sensitive hashing
- High-Dimensional space에서 이런 문제 풀 때는 당연히 LSH!(구글 사람 아니랄까봐...)
- 일반적인 Hashing 개념은 아시쥬?
- 보통 LSH 라고 하면, Jaccard Similarity 가 높은 원소들을 같은 버킷에 넣는 해쉬 알고리즘을 이야기 함(Minhash 이용해서 signature matrix 만들고 밴드 파티셔닝 하고...)
- 하지만 이 논문에서는 2015년에 발표된 "Practical and optimal LSH for angular distance" 방법을 이용
- fix a random matrix R ( size : [dk, b/2] )
- h(x) = argmax([xR; -xR]) where [u;v]
- 간단히 설명 하면, 버켓 사이즈의 1/2개 만큼의 랜덤 벡터(dk 사이즈)를 만들어 두고 그걸 곱하면 나오는 값이 미리 정해둔 버켓들중 같은 버켓에 계속 같이 들어가면 비슷한 것이라는 가정.
LSH attention
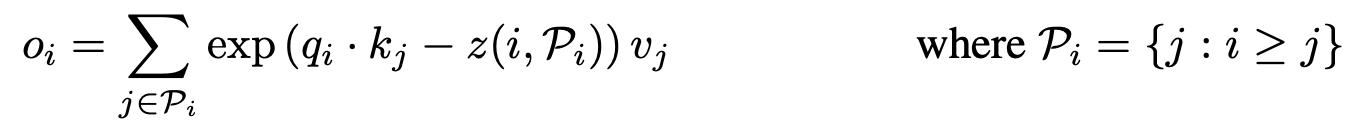
- single query position i at a time
- Pi = i번째 쿼리가 어탠션 할수 있는 Key set
- z = partition function
- 결국 위의 식이 의미하는 바는 각 query는 자신의 포지션(i)보다 작은 key에만 어탠션 할수 있다는 의미
- 자기 자신의 값을 왜 뺀건지는 밑에서 설명 됨.
- For batching
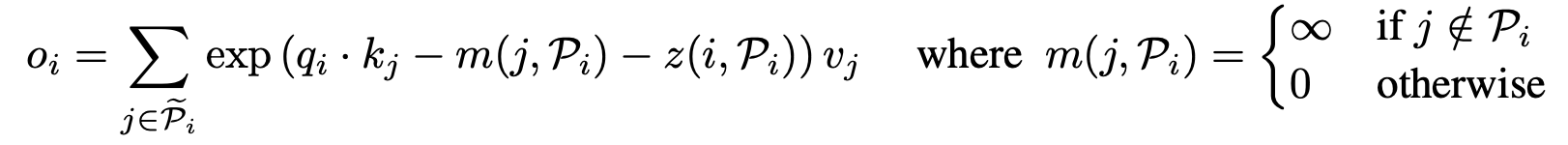
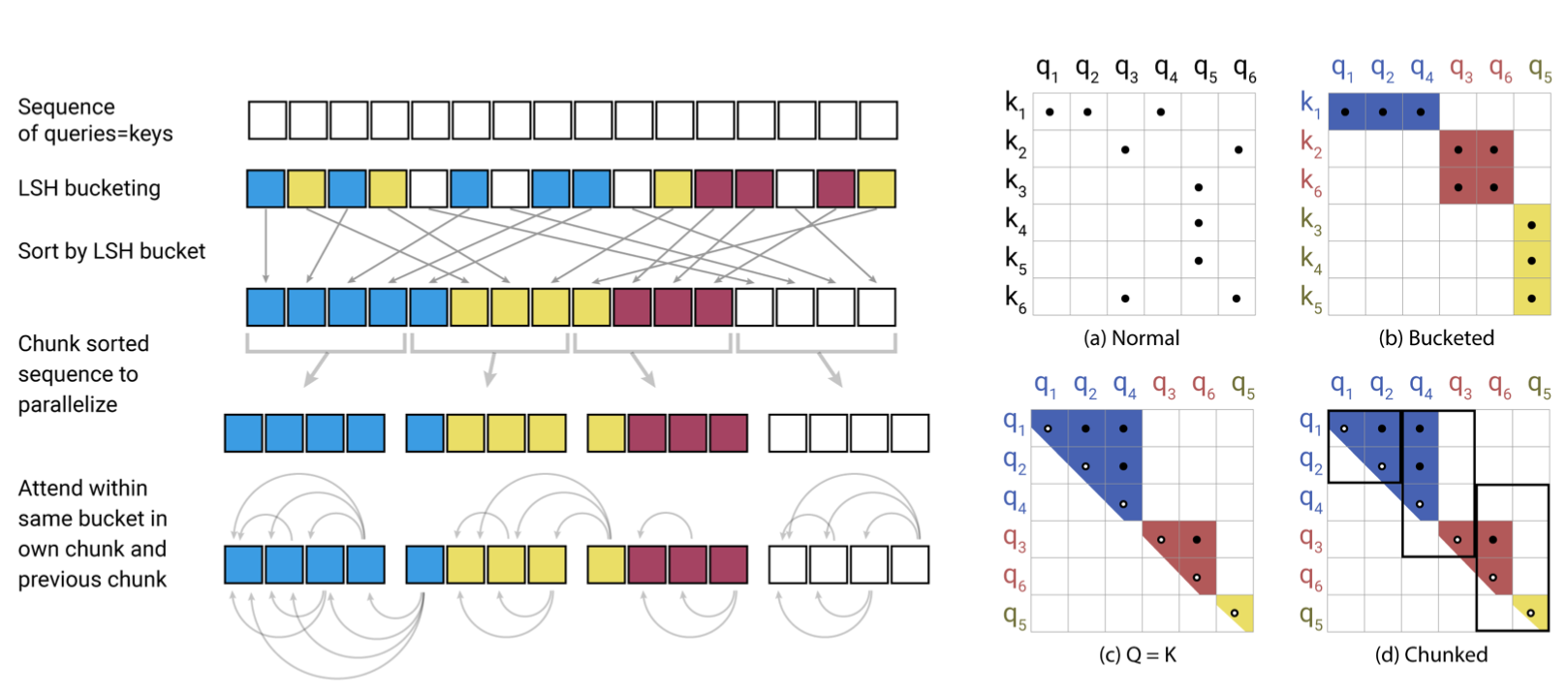
Multi-round LSH attention
- 해시를 쓰면 비슷한 아이템이 다른 버킷에 들어갈 확률이 매우 낮아 지는데,
- 이 확률 또한 완전히 없애기 위해서 Multi-round LSH attention을 사용.
- (내생각)걍 해쉬펑션 여러개 두고 돌려서 보팅하는 개념인듯.
Causal masking for shared-QK attention.
- 일반적인 Transformer에서는 자기자신을 포함해서 어탠션 가능.
- 그러나 Q==K인 상황에서는 맞지 않음.
- 그래서 K가 한 개인 경우(예 : 순서의 첫번째 토큰)를 제외하고는 자기자신은 어탠션 하지 않도록 함.
3. Reversible Transformer
- 위에서도 이야기 했지만, residual network를 사용하기 때문에 레이어가 깊어 질수록 activation 저장량이 많아짐 : 이 부분을 해결해 보고자 함.
RevNet
- Residual Network는 다 아실꺼라 믿습니다
- 2017년에 나온 논문 "The reversible residual net- work: Backpropagation without storing activations"
- 시간이 좀 오래 걸려도 메모리 사용량을 줄여보자
- 결국 잔차연결은 레이어의 입력값과 레이어의 출력값을 더해서 다음 레이어의 입력으로 넘기는 개념.
- 아래 그림과 같이 구성하면, 마지막 엑티베이션 값에서 부터 서로를 빼가면서 복원 가능.
- (내생각)사실 2017년에 이 논문을 처음 읽었을 때는, 메모리 더 써서 중간과정 저장해 두고 여러번 계산 안하게 해서 속도 빠르게 하려던 기존 대부분의 방법론(다이나믹 프로그래밍 같은)을 역행하는 느낌이었고, 아이디어는 좋은데, 메모리 기술은 발전하고 싸질꺼니깐 최대한 메모리 많이 쓰고 속도 빠르게 하자는 요즘 세상에 이게 사용 될까 했는데.. 결국 이렇게 쓰이는 날이 오는 구나 싶었음.
- 계산량이 33%정도 늘어남
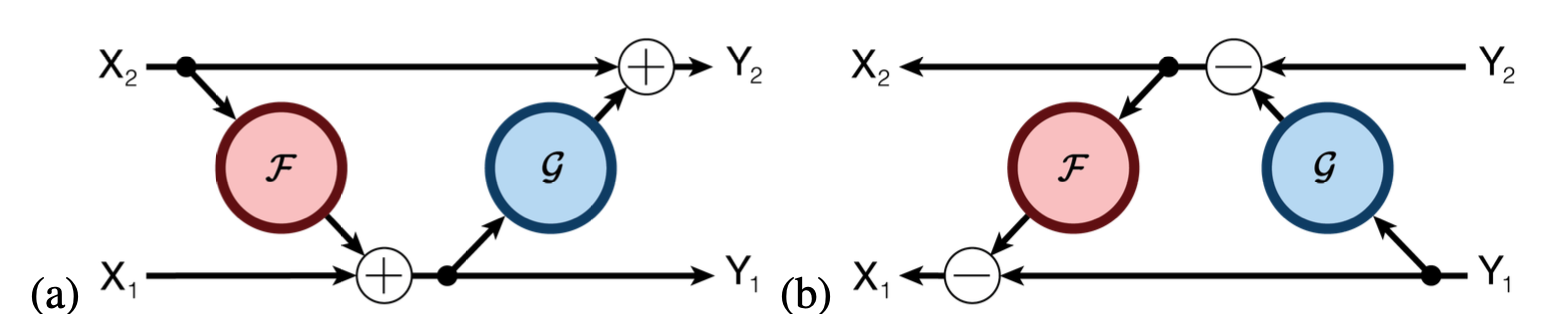


Reversible Transformer
- 위의 방법을 그대로 인코더에 적용하면 아래와 같이 됨.

Chunking
- Feed-Forword layer에서 사용하는 메모리를 줄이자!
- FF-layer는 위치와 독립적이기 때문에 청크로 잘라서 계산 가능

Chunking, large batches and parameter reuse
- Chunking 및 RevNet을 이용하면 전체 네트워크를 학습할 때 사용하는 메모리는 레이어 수와 무관함.
- 파라메터수도 마찬가지 ⇒ 컴퓨팅 되지 않는 레이어의 파라메터들은 CPU 메모리로 교환
- 일반적인 Transformer에서는 CPU로의 메모리 전송이 느리기 때문에 비효율 적.
- Reformer에서는 길이를 곱한 배치 사이즈가 훨씬 큼 ⇒ 파라메터를 사용하여 계산 한 양은 전송 비용을 증가.
- b = 배치수, l=입력길이, nl = 레이어 수, nc = 청크 개수, nr = 해쉬 반복 수, nh = 헤드수

5. Experiments
- 저자가 말했던 것들을 하나씩 비교하면서 자신이 맞다는 것을 증명.
- 앞에서 말했던 데로 enwik8과, imagenet64를 가지고 실험.
- bpd는 "bit per dim"
- 사실 자연어 처리 쪽에서는 잘 사용되는 메트릭이 아니라 당황.
- (내생각)하나의 디멘전을 저장하는데 얼마의 비트가 필요한지의 느낌.
- (내생각)어차피 학습이 되면 될 수록 작은 공간으로 같은 정보를 잘 표현할수 있어질 것이다.. 뭐 이런 느낌인듯 싶다.
Effect of sharing QK
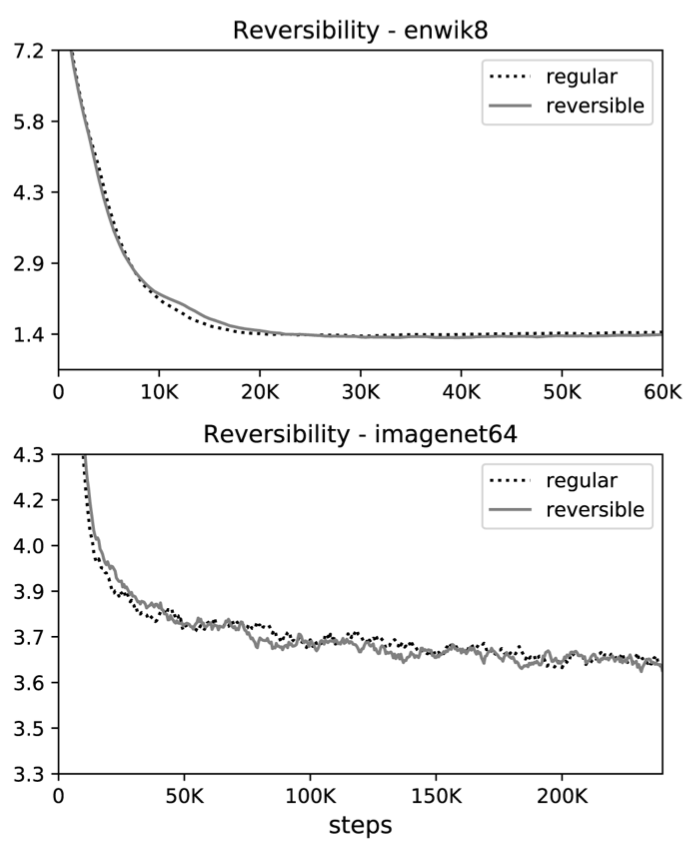
Effect of reversible layers
LSH attention in Transformer
Large Reformer models



댓글