Author
- Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning
Abstract
- MLM 방식은 입력 토큰을 손상 시킨 후 오리지널 토큰으로 수정 하면서 학습을 진행 (예 : BERT)
- 다양한 다운 스트림 테스크로 트랜스퍼 되는 관점 에서는 효과적일 수 있지만, 일반적으로 많은 양의 컴퓨팅을 요구함
- 대안으로 좀더 나은 방식을 제안 : "Replaced token detection"
- MASK 토큰을 쓰는 대신 미리 학습해둔 작은 뉴럴넷을 통해 생성된 유사한 단어를 사용
- 해당 토큰 자리의 원래 토큰을 예측하기 보다, 각 토큰이 제너레이터 샘플로 대체 되었는지 여부를 측정하는 형태로 학습
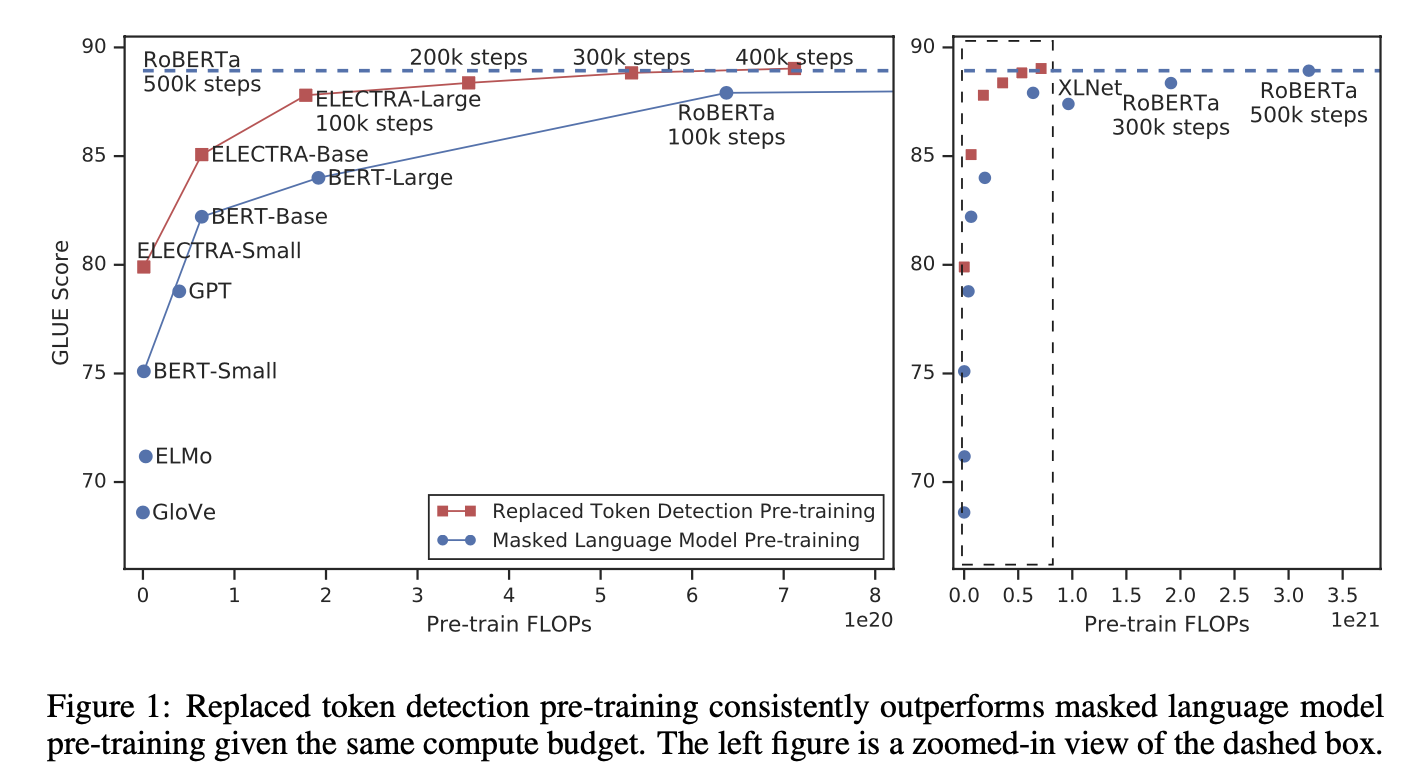
- 실험을 통해 MLM보다 더 효율 적임을 보임
- Objective가 sub-sequnce가 아닌 모든 입력 토큰에 걸쳐 수행 되기 때문이라고 함.
- 그렇게 때문에 동일한 모델 크기, 데이터 및 컴퓨팅 능력으로 진행한 BERT나 XLNet를 능가한다
- 이점은 소형 모델일 경우 매우 큰 장점임
- GLUE(NLU Benchmark) : 1개 GPU써서 4일(GPT모델 1/30)
- RoBERTa의 1/4
1. Introduction
문제점
- 최근 SOTA LM 대부분이 Denoising autoencoder 형태
- Bidirectional representation 방법 보다 효과적이지만, 하나의 학습 예제당 15%의 토큰으로만 학습
⇒ 계산 효율이 좋지 않음 - Objective 종류에 따라 Pre-Train 단계와 Down-Stream Task로 트랜스퍼 된 이후 단계의 차이가 발생 할 수도 있음.
대안
- "Replaced Token Detection" 이라는 방법을 제시
- 이 방법은 성능도 좋지만 학습 효율이 매우 좋음
2. Method
Overview - Replaced Token Detection
- 크게 두개의 뉴럴넷("Generator G"와 "Discriminator D" ) 으로 구성 됨
- G는 MLM 방식으로 학습
- D는 G가 생성한 단어를 포함하여 각 단어가 원본 문장과 맞는지 아닌지를 판별하는 형태로 학습
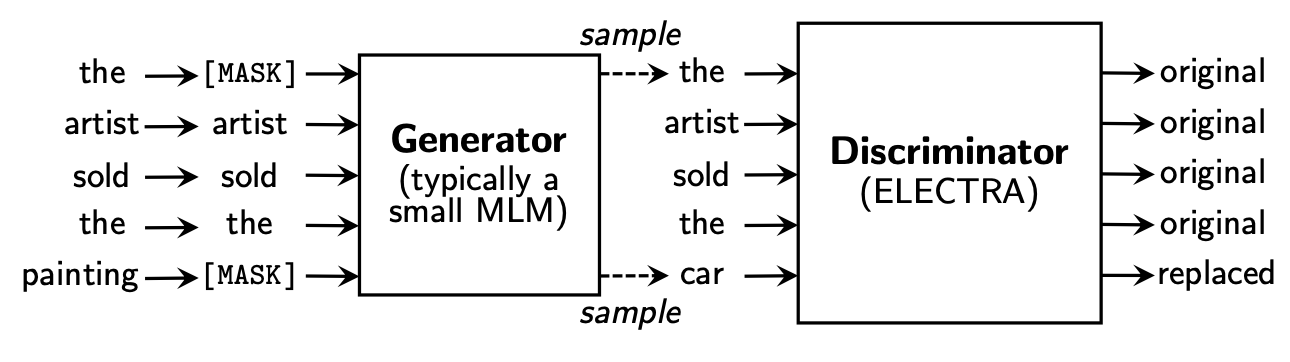
GAN과의 차이점
- GAN의 경우는 G와 D가 적대적으로 학습하지만, ELECTRA의 경우 G와 상관없이 original text와의 maximum likelihood를 학습
⇒ Generator가 우연히 정확한 토큰을 생성한 경우, 해당 토큰은 "fake"가 아닌 "real"로 간주됨. - Generator가 이런식으로 학습 되는 것보다, 적대적으로 학습하는게 Discriminator를 더 나쁘게 할 수 있음.
(Generator의 성능이 100%가 되어버리면 문제가 됨) - 그리고 GAN을 위해 많이 사용 되는 노이즈 벡터를 추가하는 방법은 사용하지 않음.
3. Experiments
3.1 Experimental setup
- GLUE와 SQuAD에 대해서 실험 진행
- Base 모델은 BERT와 비슷한 데이터로 pre-train 진행
(3.3Billion tokens from Wikipedia and BooksCorpus) - Large 모델은 XLNet 데이터 사용
(33Bilion tokens : Base + ClueWeb, CC, Gigaword) - 모델 아키텍쳐 및 대부분의 하이퍼 파라메터들은 BERT와 비슷하게 했음
(in fact, our pre-trained weights are drop-in replacements for BERT’s) - GLUE fine-tuning시에 simple linear classifier를 ELECTRA의 상단에 추가함
- SQuAD 를 위해서 XLNet에서 사용된 QA 모듈을 ELECTRA 상단에 추가함
(정답의 SP와 EP를 독립적으로 찾지 않고, 정답이 있는지 없는지를 분류함 : 2.0을 위해서) - GLUE의 일부 평가 데이터 셋이 매우 작아서, fine-tuning된 모델의 정확도는 랜덤 시드에 따라 크게 변화할 수 있음 : 10개의 fine-tuning 모델의 평균값을 사용함.
3.2 Model Extensions
Weight Sharing
- 모델의 효율성을 높이기 위해 Generator와 Discriminator 간의 weight를 공유 하고자 함
- 3가지 형태로 나누어 실험 진행
- 실험 방법 : 500K step 훈련 후 GLUE 점수
- 3가지 형태 및 GLUE 점수
- 가중치를 공유하지 않는 경우 : 83.6
- Token Embedding만 공유 : 84.3
- Encoder의 가중치를 공유하는 경유 : 84.4 (G와 D의 사이즈가 같아야 함)
- 실험 결과를 보면...
- Discriminator는 입력된 단어(혹은 생성된 단어)에 대해서만 업데이트 하지만, Generator는 모든 토큰 임베딩을 업데이트 하기 때문에 토큰 임베딩을 공유하는 것이 효율 적임.
- 인코더를 모두 공유하는 것은 아주 약간의 성능 향상이 있지만,
그것을 위해 G와 D가 같은 사이즈를 유지해야 한다는 강제가 생김. - 즉, G와 D가 같은 사이즈를 유지하는 것이 좋다면, Encoder까지 공유,
아니라면 Token Embedding 까지 공유.
- 근데, 밑에 나오지만 해보니깐 G는 좀 작게 쓰는게 더 좋더라! 그래서..
- 결론 : Small size의 Generator를 쓰고 Embedding 값만 공유
- 공유되는 Embeddings : Token embeddings, Positional embeddings
- 이 경우 Discriminator의 hidden states size를 사용
- Generator 에 linear layer를 추가
Smaller Generators
- G와 D의 사이즈가 같다면, MLM 하나만 가지고 하는 것 보다 2배의 계산이 필요
⇒ Smaller generator를 고려 - 다른 하이퍼 파라메터를 유지하면서 레이어 크기를 줄이는 형태를 시도
- 학습 말뭉치의 빈도에 따라 fake token을 생성하는 "Uni-gram" generator도 고려 해봄.
- Generator가 너무 강하면 Discriminator에 입력되는 라벨이 너무 Bias 해 질수 있음 : 너무 도전적인 과제가 되어 효과적으로 학습하는 것을 방해한다고 추측
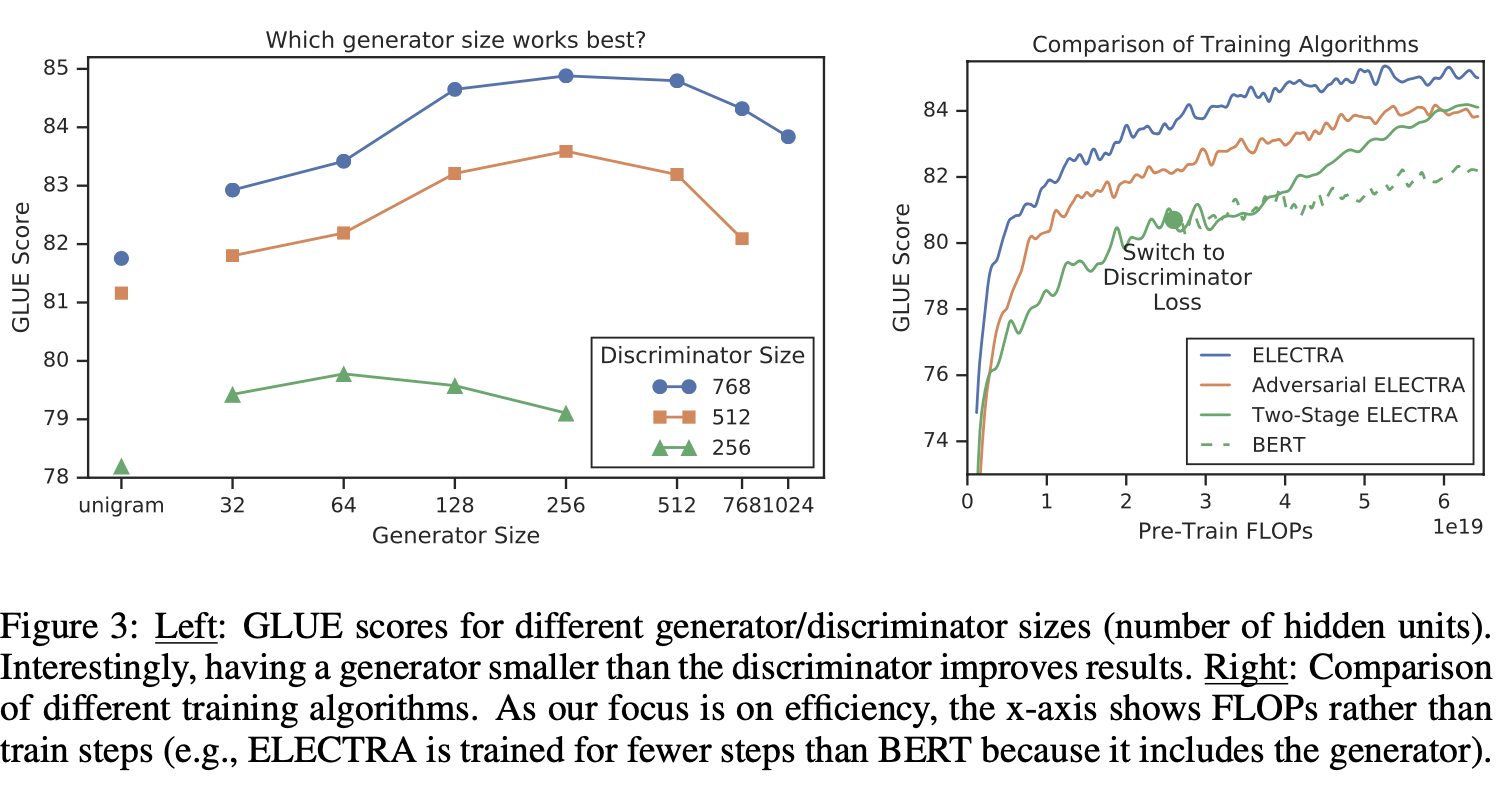
Training Algorithms
- ELECTRA에 다른 학습 알고리즘을 제안 : 하지만 결과는 향상되지 않음
- Two-Stage ELECTRA : G와 D를 함께 훈련하는 대신 2단계에 걸쳐 진행
- N step 만큼 G만 학습
- D를 G의 weight로 초기화 ⇒ G는 고정시키고 D만 학습
- Adversarial ELECTRA : GAN 버젼
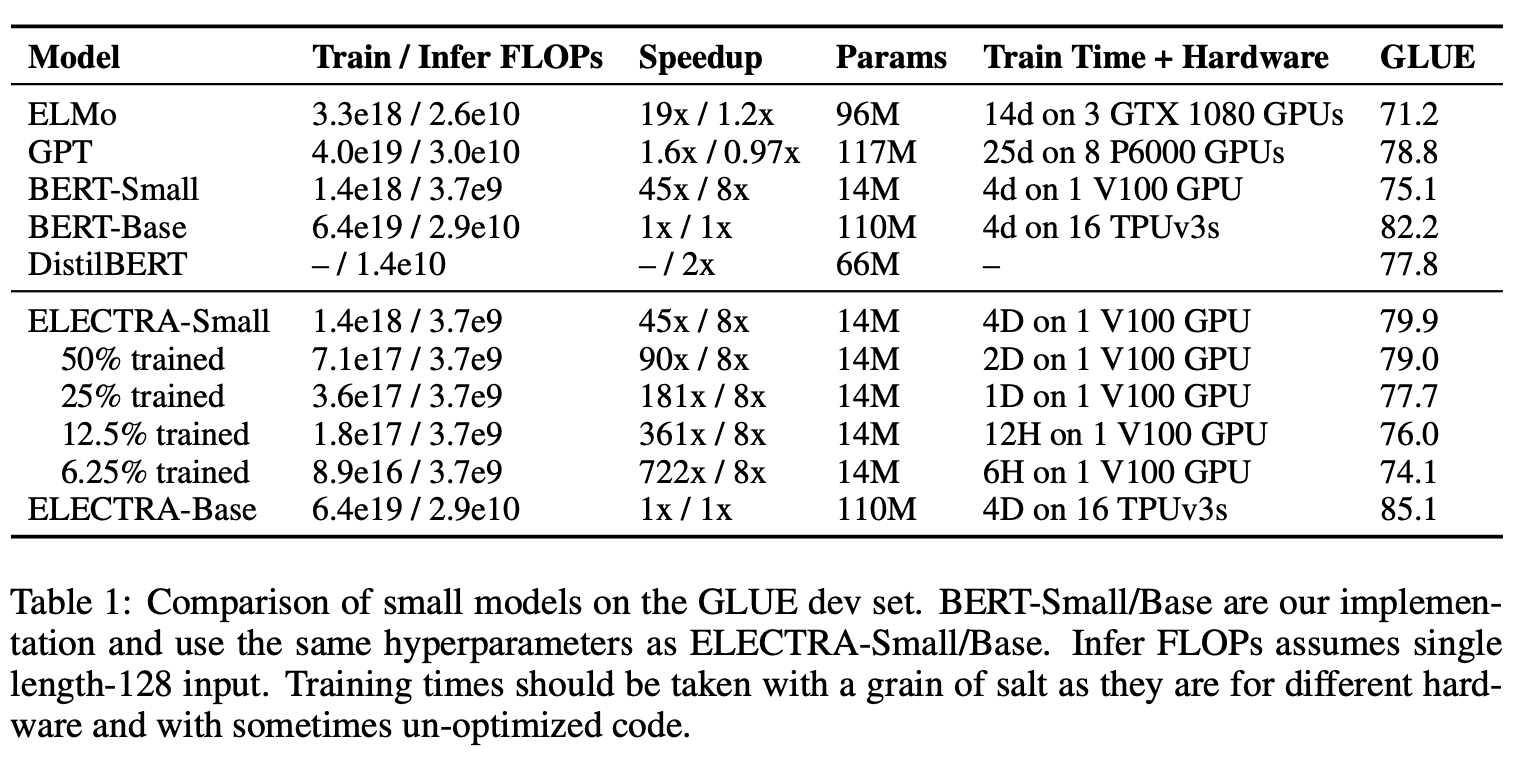
3.3 Small Models
- Pre-Train의 효율을 높이기 위해 단일 GPU에서 빠르게 훈련할 수 있는 작은 모델을 개발하는 것이 목표
- BERT-base를 기준으로 하여 하이퍼 파라메터들을 줄여가며 실험
- 시퀀스 길이 : 512 to 128
- 배치 사이즈 : 256 to 128
- Hidden State : 768 to 256
- 토큰 임베딩 사이즈 : 768 to 128
- 공정한 비교를 위해 동일한 하이퍼 파라메터를 사용해서 BERT-Small 모델도 학습
- ELMo와 GPT, DistilBERT와 비교
- 성능 자체도 매우 좋으며 학습 수렴도 매우 빨리 된다는 장점(BERT-Small과 비슷한 성능이 6시간 이내).
3.4 Large Models
- 효율성 대신 SOTA 찾기
- ELECTRA-Large 는 BERT-Large와 같은 사이즈
⇒ 400k step with batch size 2048 on XLNet data - GLUE : 로버타의 1/4만의 학습만으로 비슷한 성능을 보임
- SQuAD : 연속된 토큰에 대한 처리를 추가하는 것이 향후 숙제.
⇒ 그럼에도 불구하고 비슷한 성능
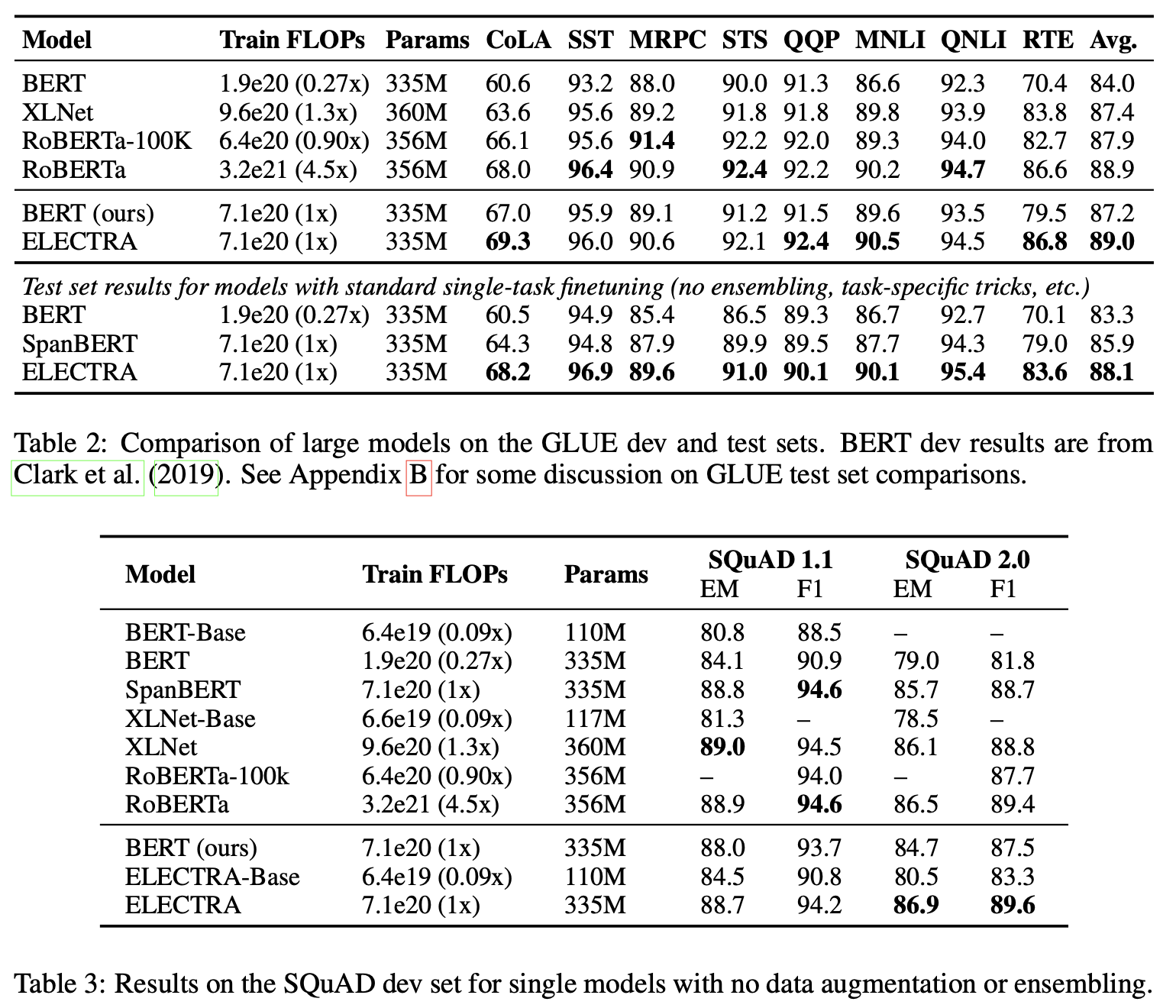
3.5 Efficiency Analysis
- 논문의 처음에서 MLM이 비효율이라고 가정 ⇒ 그러나 이것이 확실한 지를 알고 싶다.
- 해당 부분을 해결하기 위해 3가지 실험을 진행
- ELECTRA 15% : ELECTRA와 동일한 구조지만, D에서 15%만 처리(생성된 애들만)
(D에서 랜덤하게 처리도 해봤는데 더 않 좋았음) - Replace MLM : MLM에서 [MASK] 토큰을 안쓰고 미리 학습해둔 generator가 출력한 단어를 사용
- All-Tokens MLM : 모든 토큰에 대해서 Replace MLM을 진행
- ELECTRA 15% : ELECTRA와 동일한 구조지만, D에서 15%만 처리(생성된 애들만)
- 모든 토큰에 대해 학습하는게 이득
- [MASK]토큰을 쓰게 되므로써 생기는 학습과 튜닝의 불일치가 성능 저하를 준다는 것을 증명.
⇒ 이걸 해결 하기 위해 BERT 는 10%의 임의 토큰 대치를 쓰지만, 그것만으로는 부족 - All-Tokens MLM에 비해 ELECTRA의 성능이 높음.
- 원인 파악을 위해 다양한 모델 크기에 대해 BERT와 ELECTRA를 비교
- ELECTRA의 이익은 모델이 작아 질수록 커짐
- 소형 모델 일수록 완전히 수렴되도록 훈련되어질 수 있음.
- ELECTRA가 완전히 훈련 된 경우 BERT보다 높은 다운 스트림 정확도를 달성 함을 보여줌.
- ELECTRA는 차별적 분류기로 훈련되어 전체 데이터 분포를 모델링 할 필요가 없기 때문에 BERT보다 GLUE에 대해 더 좋을 것 같음.
- 결과
4. Related work
Self-Supervised Pre-training for NLP
Generative Adversarial Networks
Contrastive Learning
'Study > NLP, DL, ML...' 카테고리의 다른 글
| Reformer : The Efficient Transformer (0) | 2020.02.08 |
|---|---|
| Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer(T5) (0) | 2020.02.08 |
| Cross-lingual Language Model Pre-training (0) | 2020.02.08 |



댓글